近日,公共管理学院在知识产权服务大模型研究领域取得进展,该项目依托于国家知识产权战略实施(大连理工大学)研究基地,结合目前大语言模型技术进步以及知识产权服务领域的业务需求,与计算机科学与技术学院信息检索研究室开展合作,由林原、丁堃、王欢明、杨中楷、许侃、王琪尧、许晨曦、杨亮、林鸿飞等团队成员共同协作完成研发知识产权服务大模型——“太保”。
“太保”知识产权服务大模型概述
“太保”聚焦高水平科技自立自强和创新发展背景下利用人工智能技术赋能知识产权服务行业,旨在满足社会知识产权服务的多元化需求,为技术发明创新工作提供辅助支持,突破自然语言处理和文本挖掘的应用局限,探索大模型分析知识产权数据的新范式,在知识产权创造、管理、运用和保护等服务方面通过知识产权服务问答、知识产权法律咨询、专利分析、专利文本翻译等形式提供更加快捷的信息服务。
当前“太保”的模型基座是Qwen-7B。该模型基座是阿里云研发的通义千问大模型系列的70亿参数规模的模型,在超过2万亿tokens数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。
具体太保项目电脑端体验见地址:http://taibao-ip.help/
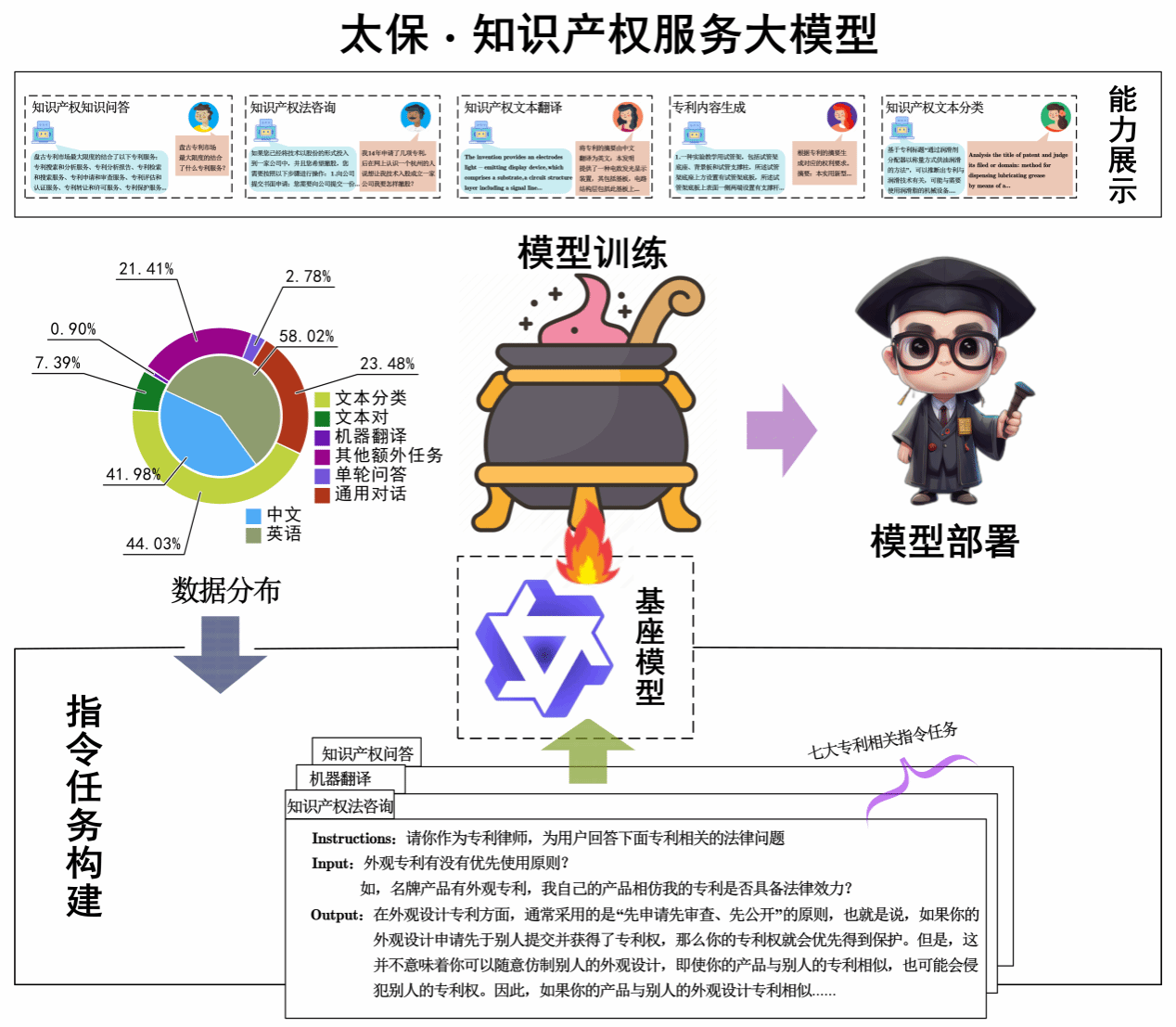
图1 “太保”知识产权服务大模型整体框架图
“太保”知识产权服务大模型的特点
·中英双语训练:通过丰富的中英双语任务指令数据(超过10W条样本)进行大模型指令微调,使模型具备了出色的中英双语知识产权相关问题智能问答、知识产权咨询对话、知识产权中的专利摘要/权利要求生成、知识产权文本分类、知识产权文本翻译、标题生成等多种知识产权分析能力。
·专业问答:所采用训练数据涵盖了丰富的专业知识和信息,便于大模型能够理解术语、语法、语境等,从而更加准确地处理和回答知识产权领域的各种问题。同时,在模型训练过程中通过优化算法进行不断调整和优化,使得模型更好地适应知识产权领域的数据分布和任务需求,提供较好的知识产权服务。
·泛化能力:除了知识产权领域,模型仍具备通用领域对话能力,并通过设计指令模板多样性,使模型具备了较优秀的指令理解能力,在同类任务的不同场景下具有较好的泛化能力,并激发了模型一定的零样本学习能力。
“太保”知识产权服务大模型应用示例
本项目围绕知识产权创造、管理、保护和运用四个主要环节研发知识产权大模型,以期提供更加全面系统的公共产权智能服务。(1)在知识产权创造方面,提供内容生成(摘要、标题、权利)、知识产权文本中英文互译等功能服务。(2)在知识产权管理方面,提供知识产权智能问答、知识产权文本分类及正确性判断、知识产权相关性辨析、知识产权政策制度咨询等功能服务。(3)在知识产权保护方面,提供知识产权法咨询、知识产权申请咨询等服务。(4)在知识产权运用方面,提供知识产权转让咨询、知识产权转化咨询等相关服务。

图2 “太保”知识产权服务大模型功能图


图3 “太保”知识产权创造服务
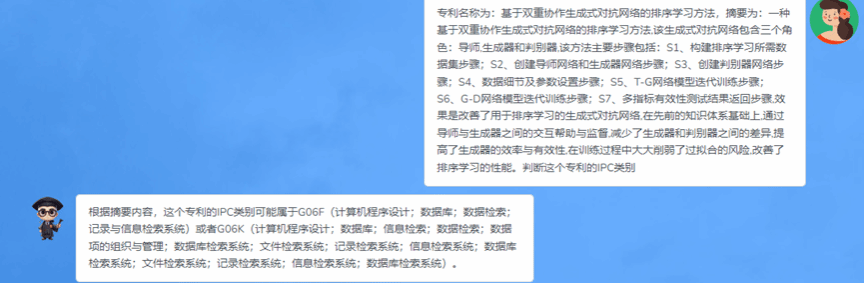
图4 “太保”知识产权管理服务
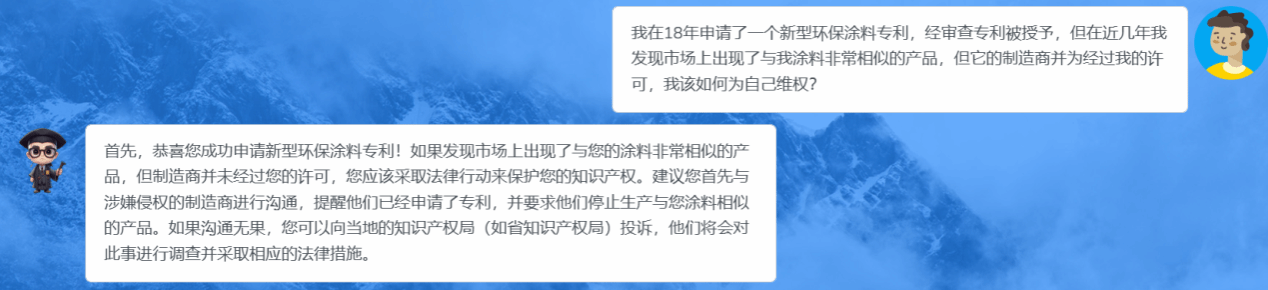

图5 “太保”知识产权保护服务

图6 “太保”知识产权运用服务
“太保”知识产权服务大模型展望
“太保”在知识产权领域展现出一定的服务能力,但仍然存在一些大型模型普遍存在的问题,例如幻觉、数据量受限、偏见、误解等问题,仍有探索与发展的空间。为了进一步提升“太保”的能力,未来的研究将着重于基于知识图谱进行大模型的实体和关系校准、基于人类反馈的强化学习提高大模型的分析能力、基于知识产权法律法规进行价值观对齐和隐私保护等方面,从而使得“太保”能够提供更高质量的知识产权服务。
编辑:王国际
审核:王欢明
